Improving Utilisation in HPC & AI – Part 4
Part 4 of mini series on improving utilisation (aka reducing unit cost) looks at adjust the supply of compute to deal with demand variability

There’s still more to say about dealing with fragmentation but before we get to that, we need to take small detour into supply elasticity in our quest to improve utilisation in HPC and AI workloads.
If your workload demand is always the same, you can ignore this. For everyone else, we’re always dealing with a fundamental mismatch. If you run only on premises (or use only long-term cloud reservations), then we have a variable demand being matched to a constant supply. At large enough scales, the effects of workload decorrelation can mean this isn’t such a problem and it is possible to maintain healthy utilisation levels, even with a fixed supply. At smaller scales or large enough levels of demand volatility though, this becomes impossible. For example, if your demand looks like this:
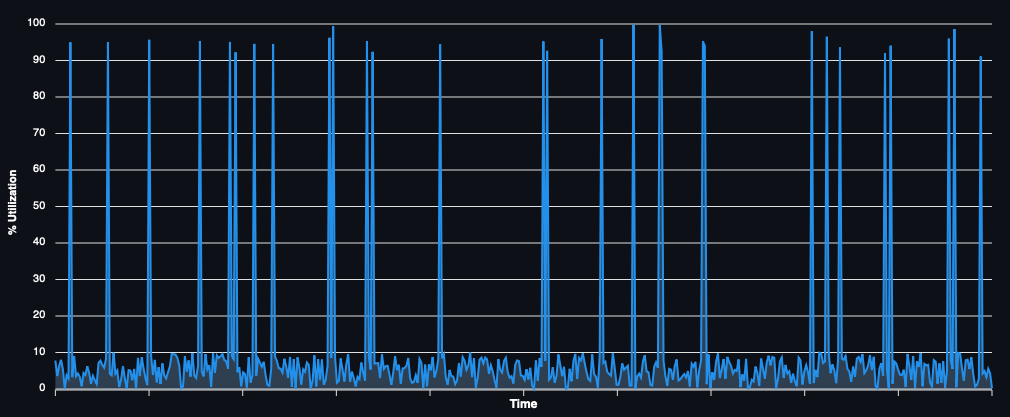
And you’re running on a fixed size of compute, with the best will in the world, your utilisation (and unit cost) will suck. The solution is to make it someone else’s problem. Use the cloud. More specifically, I mean use the cloud without long term capacity commitments, by using on-demand or more ideally, spot capacity. Also when I say cloud that includes neo-clouds and potentially even MSPs.
This is best leveraged by using on premises (or long term cloud capacity such as reserved instances) for a base load that is essentially running at close to 100% utilisation 24x7. Additional demand is then serviced by short term capacity as required. Depending on your workload (and how good your data orchestration is) this could even mean multiple clouds.
The viability of this depends on the relative cost of your base capacity vs the flexible cloud capacity and the proportion of time that the variable load operates for. This may not be a static relationship either and require adjusting over time to optimise for cost and utilisation rates.
Critically, the ability to do this coupled with workload defragmentation (I will cover that next) can significantly reduce costs.
You could write a control plane to do this yourself (or vibe code one I guess) but there are also several existing workload managers, cloud control mechanisms and other primitives that you can use to build on top of.



