Is AI actually intelligent — or just a smarter dice roll?

I first heard the idea of using LLM inference as paths in a Monte Carlo simulation at the QuantMinds conference (November 2025). The same idea has now been suggested by people from the leading AI labs including Andrej Karparthy. Just in not so many words.
Last month Andrej Karpathy release Auto Research. The idea being promoted is that an LLM, given tight validation criteria, can take a task and iteratively improve on the results and throw away anything that is wrong or produces a worse result. Not long ago I was at a private event with Anthropic presenting on the best ways to use Claude Code. One of the central points (of four) here was the importance of automated validation of the output of Claude Code.
So far nothing new here. I think those of use that have been using LLMs regularly independently came to the same conclusion too. So, we’re all on the same page, right? Almost. There’s a subtlety I missed here that I think the quants saw a year ago. I was just dismissive of it because of the cost of inference.
What no one is saying, is that if you have to gate the output of your “AI” on a validation step, is your “AI” actually intelligent? Or do you just have a better random number generator for your Monte Carlo model?
Let me try illustrating the point, probably poorly, with an example. It is possible to calculate the value of Pi just by defining a circle and generating random numbers. Draw a circle on a square piece of paper and throw 10,000 darts at it. You can now calculate the ratios of the areas (and therefore the value of Pi) by counting the number of darts inside and outside the circle.
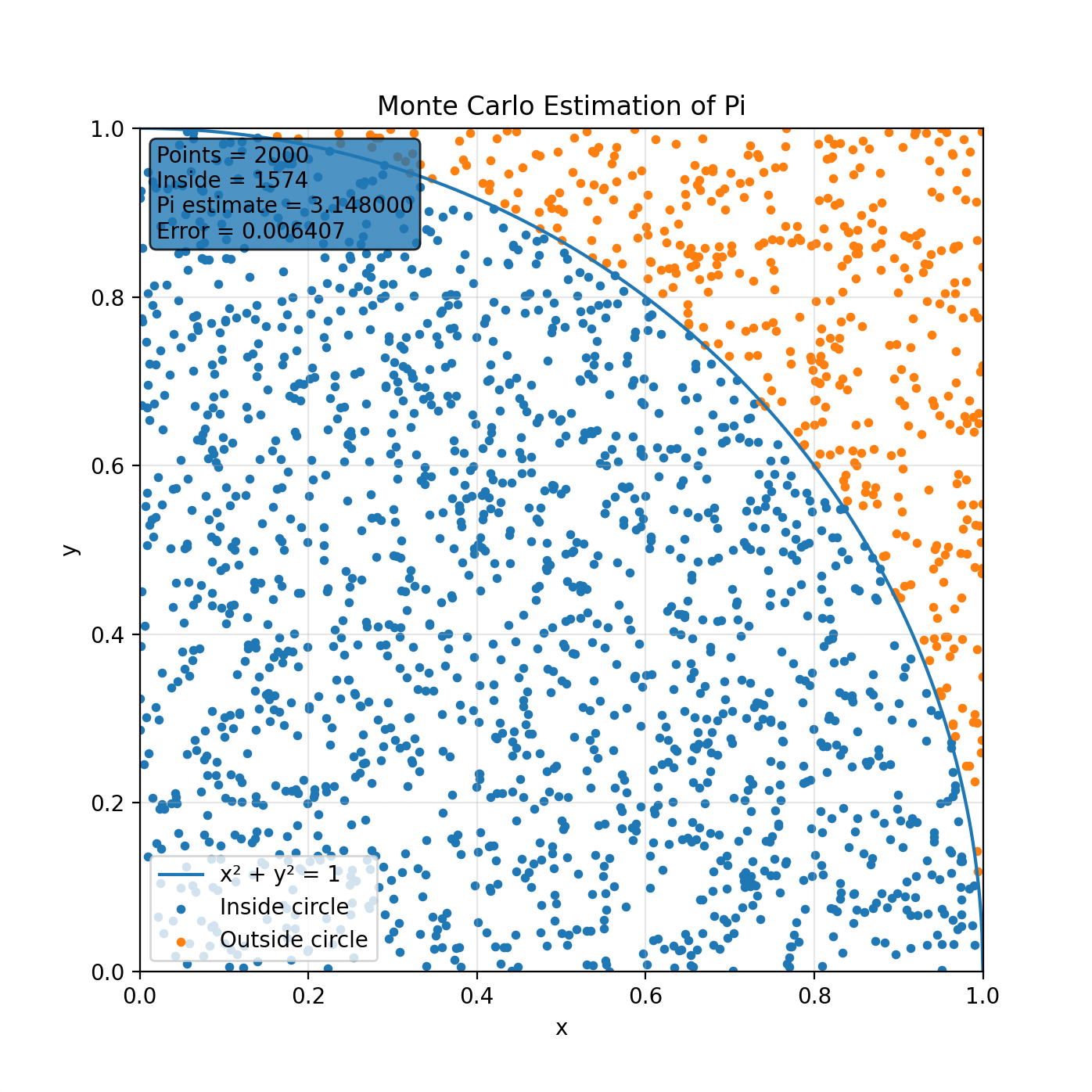
Imagine now if instead of a single circle we had two, concentric circles, one slightly smaller than the other. Like a car tyre. We can adjust the math to calculate Pi based on the number of darts that hit the tyre. The result is actually worse (less accurate) than the first method. But what if now we change the random number generator so it’s not random. So, it throws the darts mostly around the tyre. The accuracy improves (for the same number of darts or Monte Carlo paths). I have some half-baked ideas of how this might apply to equity option pricing but I’m not a quant so they’re probably wrong. Give me a shout if you are a quant though and want to talk.
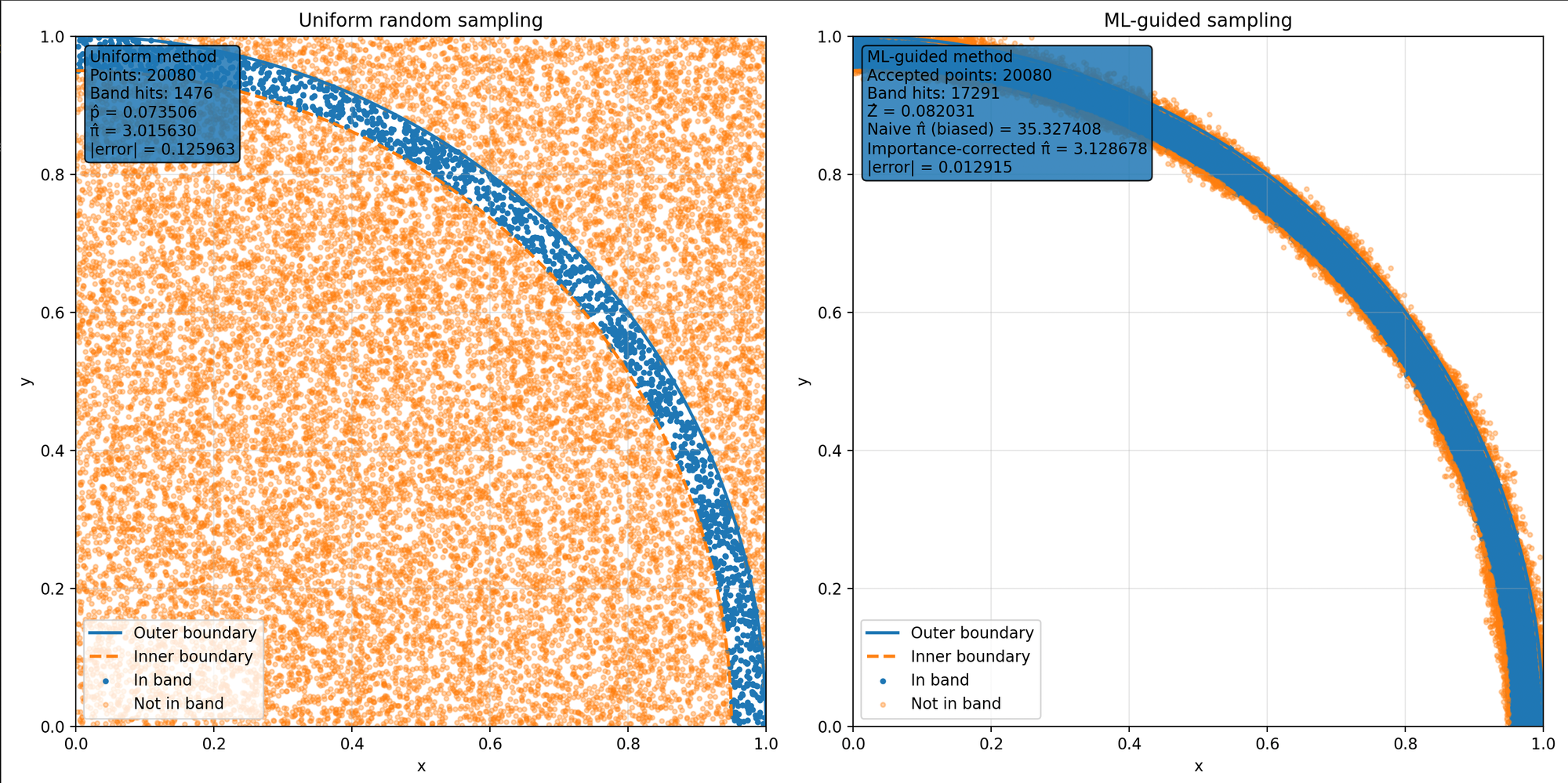
This analogy though is what we have with LLMs. A better random number generator. That’s not really random. It might even be mostly correct. But not always. So you need less throws of the dart (or MC paths).
I think the finance quants just saw this way before I did. Before most of us did. Before the AI Labs will say it out loud but will quietly point to it. I thought it was mad because the cost of one LLM inference is many thousands of times that of running a single MC path with traditional models. The cost of compute wouldn’t make sense. But Vera Rubin drastically drops inferences costs I’m told. Taalas has an ASIC that can run inference that is 100 to 1000 times faster (read cheaper) than current generation GPUs. Maybe we don’t need 10,000 paths, maybe 100 will do. Maybe this isn’t so mad. Even if it’s just for a subset of limited used cases like real time risk.
The next problem of course becomes that not everything has a simple automatable verification. For some reason this isn’t getting talked about much and when I do bring it up, people have this perplexed look on their face. Like I’m the one that’s mad. Some complex derivatives can take literal hours of expensive compute to price (though admittedly we seem to trade less and less of these weird things). Validating each fanciful idea from an LLM to see if it improved things would cost a fortune even if the inference is cheap.
Peter Higgs proposed the existence of the Higgs Boson in 1964. It took 40 years and the construction of the Large Hadron Collider at CERN to validate that idea.