COREx - A Financial Risk HPC Benchmark
Evaluating hardware performance such that it correlates well to your own use case is always difficult.Financial risk system specific benchmarks can be even more of a challenge due the proprietary and often secret nature of the code involved. This article looks at developing such a benchmark.
A previous article in this series, whilst outlining some of the complexities in running HPC on cloud, looked at the difficulty in selecting VM instances. A key challenge here being the lack of any relative performance data especially from GCP and AWS. (Azure provides a guideline by the way of Azure Compute Units). There are of course numerous commercial benchmarks available that can help achieve this, but how well do they correlate to your own HPC workload?
The best benchmark
It goes without saying, the best possible benchmark to use for any evaluation is the code you intend to run. For many reasons, this is not always possible or practical, at which point it becomes necessary to dream up an alternative that provides a representative synthetic simulation of the real workload at best, or at least a consistent, repeatable, and comparable load at worst (and, of course, your representative workload should also meet this criteria).
The purpose of the benchmark is naturally of key importance and, for us, this was clear. We needed something that would allow the comparison of infrastructure (virtual machines) from various vendors (cloud providers initially, but this could work for physical system vendors also). The required output of the comparison is to be able to compare both outright performance (which infrastructure gets the job done fastest) and cost optimisation (which infrastructure gets the job done cheapest).
For a genuine real-world comparison, we would need to define a workload and an SLA to complete that workload. The results of such a comparison, however, would be useful only to that specific use case. Our aim was to provide output that, with some basic mathematics, can be applied to your own workloads. Put another way, we didn’t want to create a benchmark that runs on 30,000 CPUs for eight hours and exercise this across various types of infrastructure. Quite apart from the costs of such a benchmark, the results would be hard to translate to other HPC systems. Instead, we chose to benchmark the performance at a machine and CPU level, i.e. the performance of a single CPU within a machine and the performance of a single machine. The results of this (provided the workload is suitably selected) should extrapolate to other systems with added benefit that the magnitude costs to run the benchmark would be significantly cheaper.
Picking a use case
This leaves us with the decision of what the synthetic workload should be. We would have loved to have picked something fun in the field of Formula 1, such as CFD or race simulations, but we have quite limited expertise this arena. We do, however, have a combined experience in excess of half a century in financial services and, whilst perhaps not as exciting, the financial services industry is a large user of HPC technology.
The majority of financial services HPC systems do one thing: calculate risk (in its multitude of guises). It was, therefore, evident that our benchmark would need to perform financial risk calculations. It goes without saying that no financial institution was going to share its secret sauce (quantitive analytics libraries) with us, so the fairly logical conclusion was to use something based on Quant Lib.
There is an existing benchmark based on Quant Lib, part of the Phoronix Test Suite from Open Benchmarking which is based on a number of units tests that form part of the Quant Lib codebase. (See this article from Microsoft about benchmarking HPC SKUs though if you want to see it being used). Bearing in mind the opening statement of this article, a number of unit tests seemed too disassociated from a real risk system and we felt a better synthetic workload could be adopted (yet still based on Quant Lib). This led to the use of Open Source Risk as our starting point. Being an open source risk engine and not a benchmark, this required us to define an appropriate set of inputs to function as a synthetic benchmark.
Financial product and risk type selection
The choices at this point get a little tricky; naturally, we are limited to products and risk types that ORE supports. Beyond this, the make-up of the input portfolio and risk outputs varies hugely from one risk system to another. We elected to create a portfolio (using the many examples provided by ORE) of all possible products. Whilst this won’t be representative of any existing risk system, it exercises a wide range of code paths and potential compiler and processor optimisations that are relevant.
How long should it run?
Another factor to consider was the run time of the benchmark (achieved by varying the number of simulations ORE performs). A typical CPU benchmark may run for only a few minutes. However, due to the nature of virtualised environments and the existence of VMs with burstable CPUs, a longer duration would provide more realistic and comparable results. Unfortunately, this would be at the expense of a larger bill! Somewhat in keeping with industry standard benchmarks, we provided the option to vary the length of the benchmark. The benchmark score is adjusted according to the number of simulations that are run and will be (approximately) the same.
To IO or not to IO
This results in a fairly CPU limited benchmark and, whilst this should be reflective of most financial risk systems in our experience, this isn’t strictly true. The overwhelming majority of financial risk systems we have worked on over the last 20 years, whilst being CPU intensive, are often IO-bound at their limits.
A truly representative benchmark would also simulate the network transfer of the input data, namely the market data, trade populations, financial model configuration parameters, counterparty data and other static data. ORE provides all of this information via a series of XML files read from local disk in our benchmark. It is possible to engineer a benchmark that would require network access to retrieve these data and to provide realistic data volumes of each and the software to do so would not be particularly complex. The additional number of variations in how that data are transferred and where they are sourced from would add a level of complexity; however, that is likely to not only to lead to spiralling runtime costs but also render the results difficult to interpret. Very deliberately, we decided to keep things simple, at least in this first iteration, and keep IO to local machine only.
Encyption and AES-NI hardware optimisations
It would also be quite difficult to find a financial risk system today operating in public cloud that is not required to ensure all its inputs and outputs are encrypted (and in the case of some financial institution actually encrypted twice). Given the existence of AES-NI hardware extensions and the prevalence of encryption in risk systems, it seemed prudent to include this as within the benchmark. As such, the input data are AES decrypted using the OpenSSL libraries and the results are AES encrypted using the same.
Slot counts
Lastly, to represent a real HPC system, a single instance of the process would be insufficient. A slot count per CPU has to be applied in order to run multiple instances of the risk engine per machine. See our HPC glossary for an explanation of slot count.
Fortunately, ORE is (unlike many real-world risk systems) single threaded and quite capable of entirely consuming a whole CPU. As such a single slot per CPU model works well.
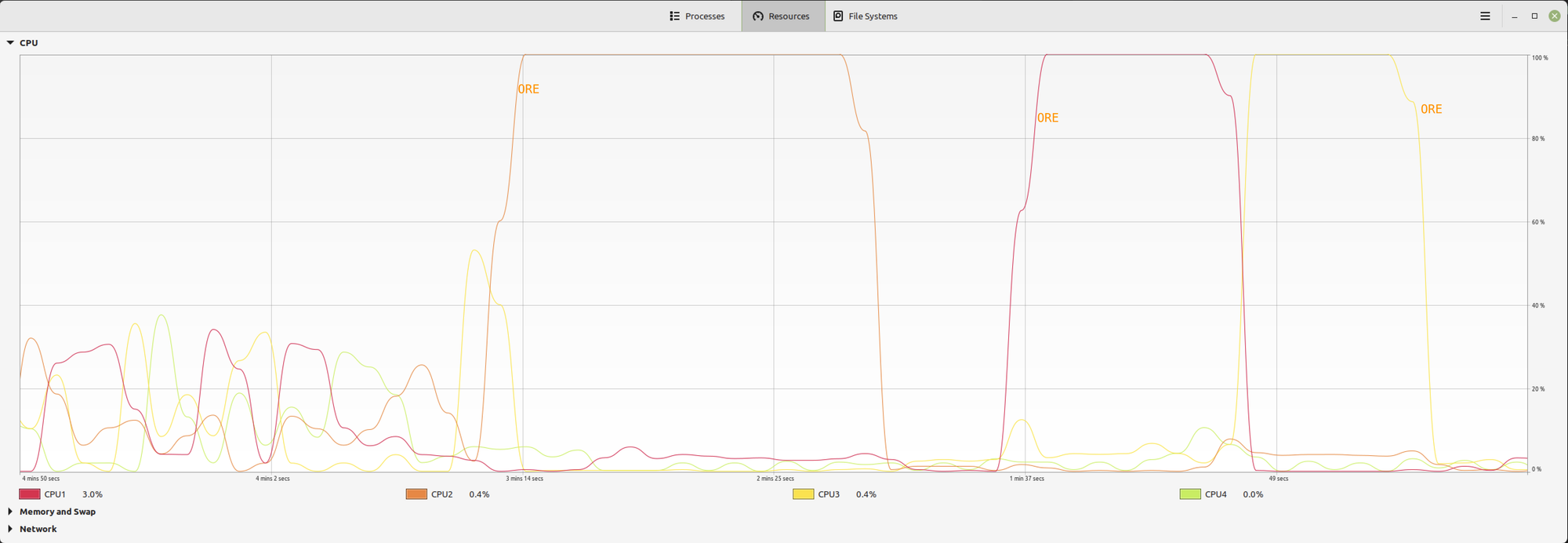
Naturally the open question in your mind at this point is SMT (Hyperthreadig to give by its Intel brand name). That requires a more in depth answer and will be the topic of a future post.
All of the above resulted in COREx. The benchmark is open source, available on GitHub and we’d be very interested in your experiences with running it should you choose to do so.



