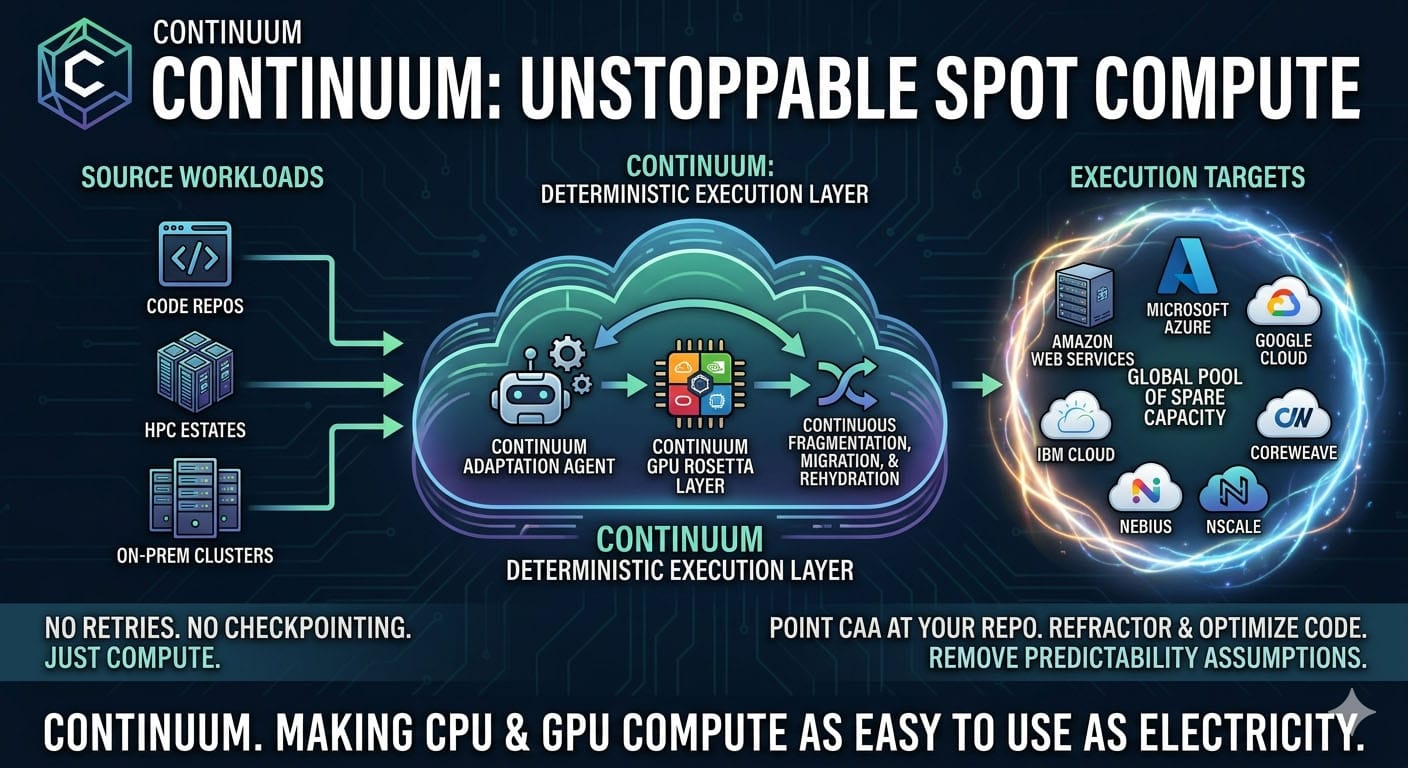
HMx Labs Announces Continuum™
90% cheaper compute that feels like On Demand VMs but is built on unused spot capacity across multiple providers.

Spot compute, but it just… doesn’t stop.
Continuum is a deterministic execution layer built entirely on top of spare capacity across Amazon Web Services, Microsoft Azure, Google Cloud, Oracle Cloud, IBM Cloud, CoreWeave, Nebius and Nscale.
Yes, we know how that sounds.
Under the hood, workloads are continuously fragmented, moved, and rehydrated across a global pool of spot instances. You no longer need to care about which or how many CPUs or GPUs you need.
No retries. No checkpointing ceremonies. No “this is fine” dashboards.
Think your workloads won’t work with this? Our Agentic Adaptation Tools say otherwise.
Just point the Continuum Adaptation Agent (CAA) at your repo.
It will:
- Refactor your code to run on Continuum
- Optimise for fragmentation, migration, and rehydration
- Quietly remove anything that assumes infrastructure behaves predictably
Not only that but you can also connect your on-prem cluster and sell spare capacity back into Continuum, turning that “idle HPC estate” into something your finance team suddenly cares about. And still use it in preference to renting someone else’s capacity.
Still stuck on CUDA and Nvidia? The CAA will refactor your code to use the Continuum GPU Rosetta Layer so you can use any available GPU or accelerator.
Continuum. Making CPU and GPU compute as easy to use as electricity.