Where AI and Machine Learning Fit in Waltz-Based Cloud Migration Planning
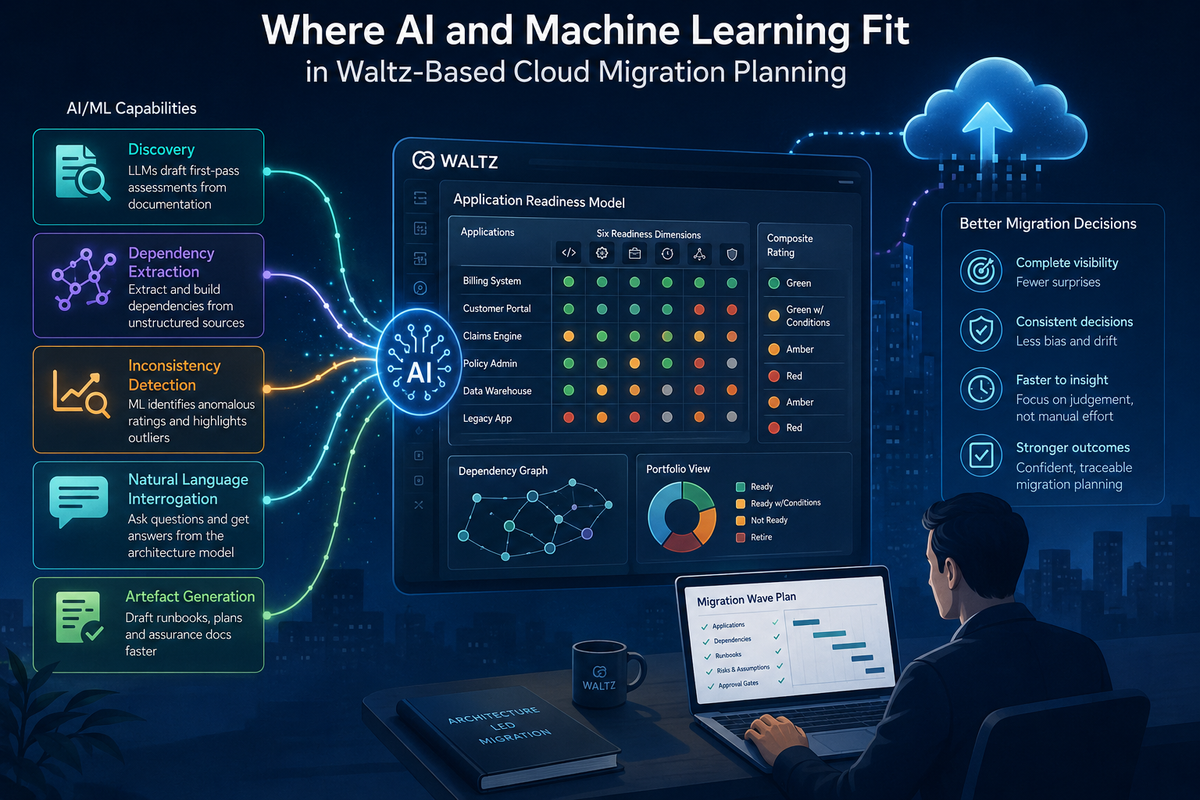
This is the fourth post in a series on architecture-led cloud migration with Waltz. Earlier posts covered the case study behind the approach, the argument that cloud migration needs enterprise architecture before infrastructure, and a practical model for assessing cloud readiness across an application portfolio. This post addresses a question that comes up in almost every conversation about that work: where do AI and machine learning fit in?
It is a fair question, and one that deserves a direct answer rather than a marketing one. The honest position is that AI and ML help meaningfully in some places, are oversold in others, and do not change the underlying architecture problem the readiness model exists to solve. This post sets out where they earn their place, where they do not, and how to think about adopting them without creating new problems in the process.
Start with what the model actually is
The readiness model described in the previous post is a structured human judgement. Applications are assessed across six dimensions: technical, operational, business, lifecycle, dependency, and regulatory using written criteria, captured in Waltz alongside the rest of the architecture context, and translated into a treatment decision through a defined rating scheme.
The work that goes into producing and maintaining that model is what AI and ML can accelerate. The judgement at the centre of it is not what they can replace. Holding that distinction firmly is the difference between using AI well and using it badly.
Where AI and ML genuinely help
Discovery: bootstrapping the first-pass assessment
The single most expensive part of building a readiness model is the first pass. Getting a baseline rating across hundreds or thousands of applications, when documentation is fragmented and the people who know each system are scattered, is months of work in a typical large estate.
Large language models are genuinely useful here. Pointed at an application's existing documentation. Confluence pages, README files, architecture diagrams, runbooks, ticket history, code repositories. They can draft a first-pass assessment against your defined criteria. The draft will not be perfect, but it will be roughly right, and the human assessor moves from author to editor. That is a much faster role.
The pattern that works is to have the LLM produce a structured output: a draft rating per dimension, with the supporting evidence cited, and explicit gaps marked where evidence was missing. The reviewer then has a starting point, knows what to verify, and can see where their judgement is being asked to fill a gap rather than override the model. Done well, this turns a months-long inventory exercise into a weeks-long review exercise.
Another key factor is that the Waltz dataset includes dataflows, applications booksmarks (to code repos, confluence, sharepoint etc), process diagrams; all of which can provide the AI structured and authoritative input.
Extracting dependencies from unstructured sources
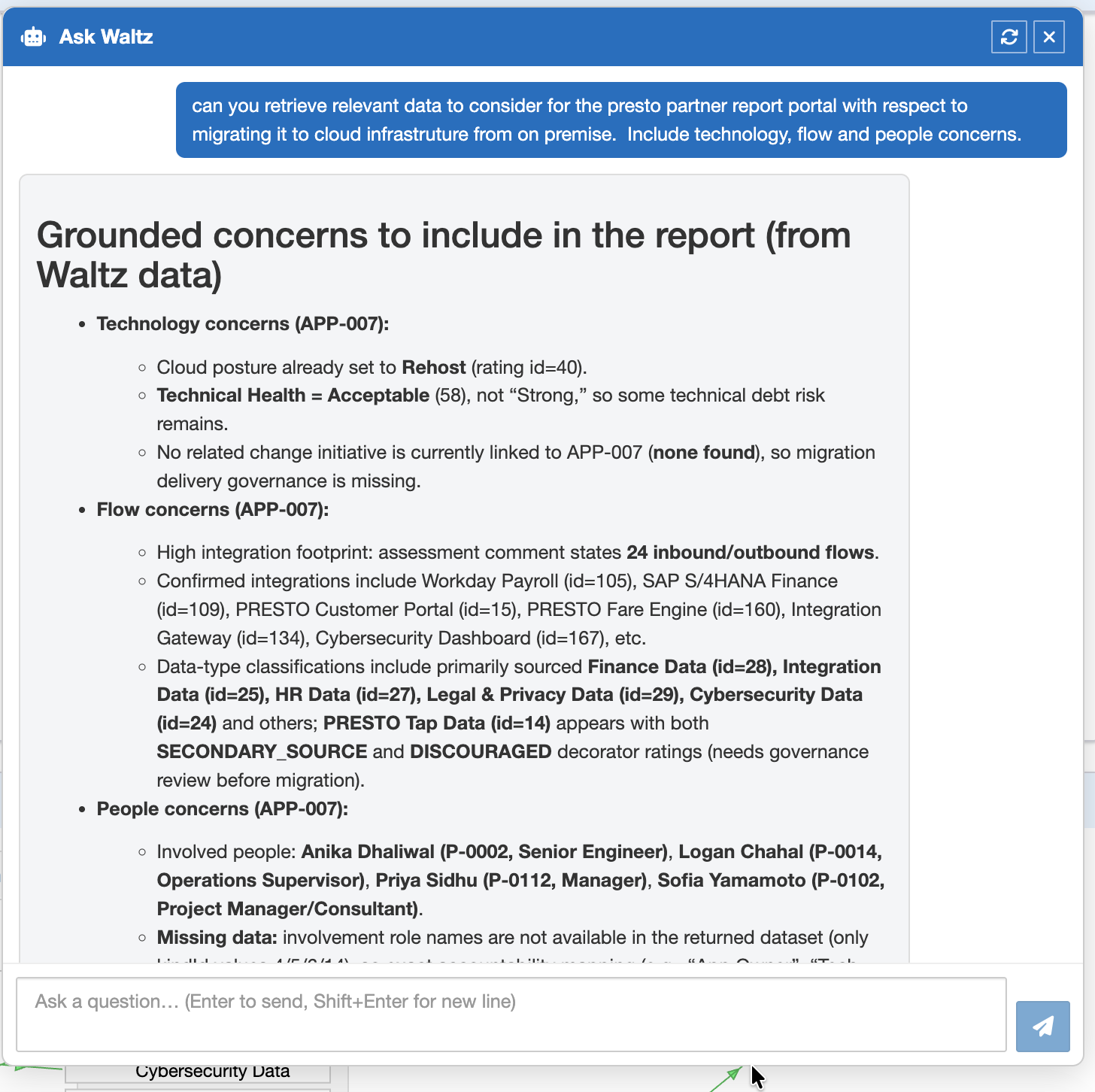
Dependencies are usually the worst-documented part of an estate. They live in connection strings, firewall rules, integration code, batch schedulers, log files, and tribal knowledge. Building a clean dependency graph from those sources is one of the slowest parts of any architecture programme.
LLMs are unusually good at reading heterogeneous text and extracting structured relationships. Combined with static code analysis, network flow data, and existing CMDB exports, they can populate a dependency graph in Waltz that would otherwise take months of interviews / surveys to assemble. The output requires validation, but you are validating a draft rather than building from nothing which is a leap!
This is also the area where AI most directly addresses a real risk identified in the case study and the earlier posts: hidden dependencies are where migration plans go wrong. Anything that improves the completeness of the dependency view materially improves the quality of the migration plan.
Surfacing inconsistencies in ratings
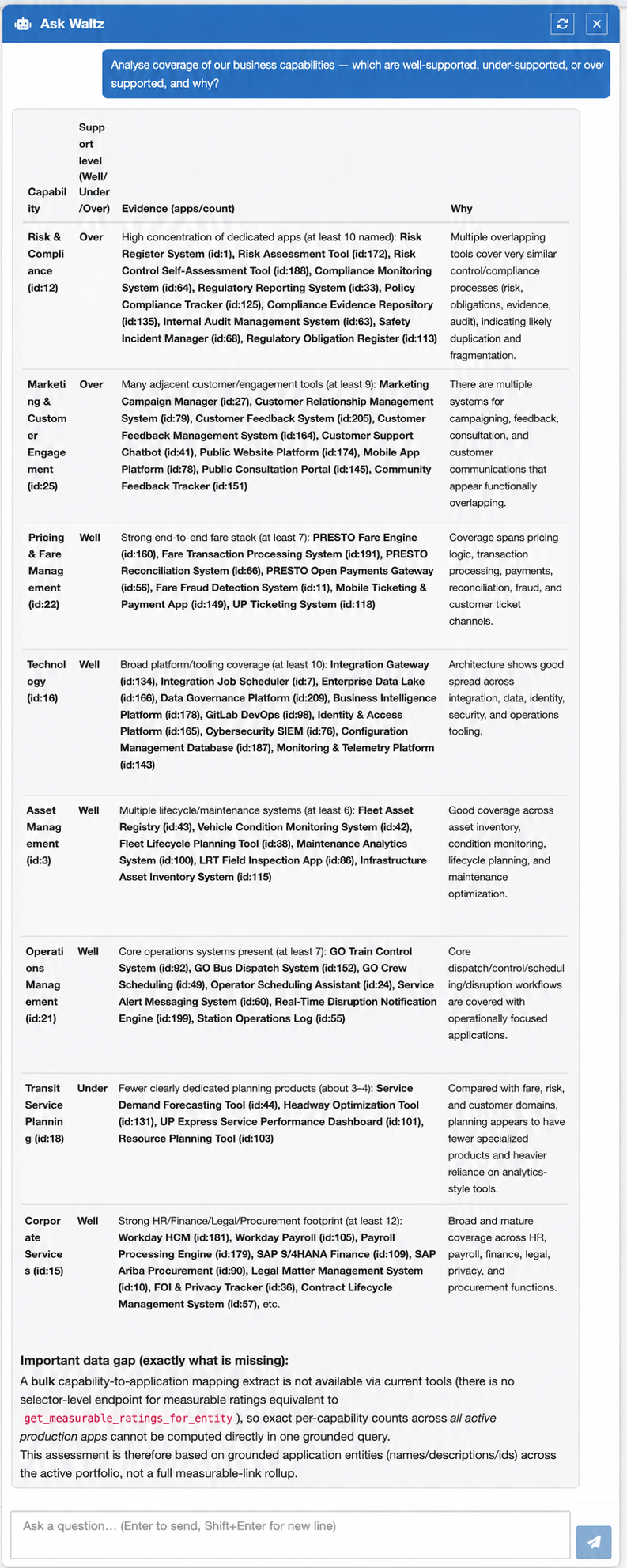
Once ratings exist across a portfolio, machine learning techniques can flag applications whose composite profile looks anomalous. If an application is rated Green on technical and operational readiness but Red on business readiness, is that genuinely the right answer or is it a sign that one team scored differently from another? Cluster analysis across rating vectors highlights outliers worth a second look.
This is unglamorous but it is exactly how a readiness model stays consistent over time. Without it, the model drifts as different teams apply slightly different interpretations of the same criteria. With it, drift is detectable and correctable.
Natural-language interrogation of the model
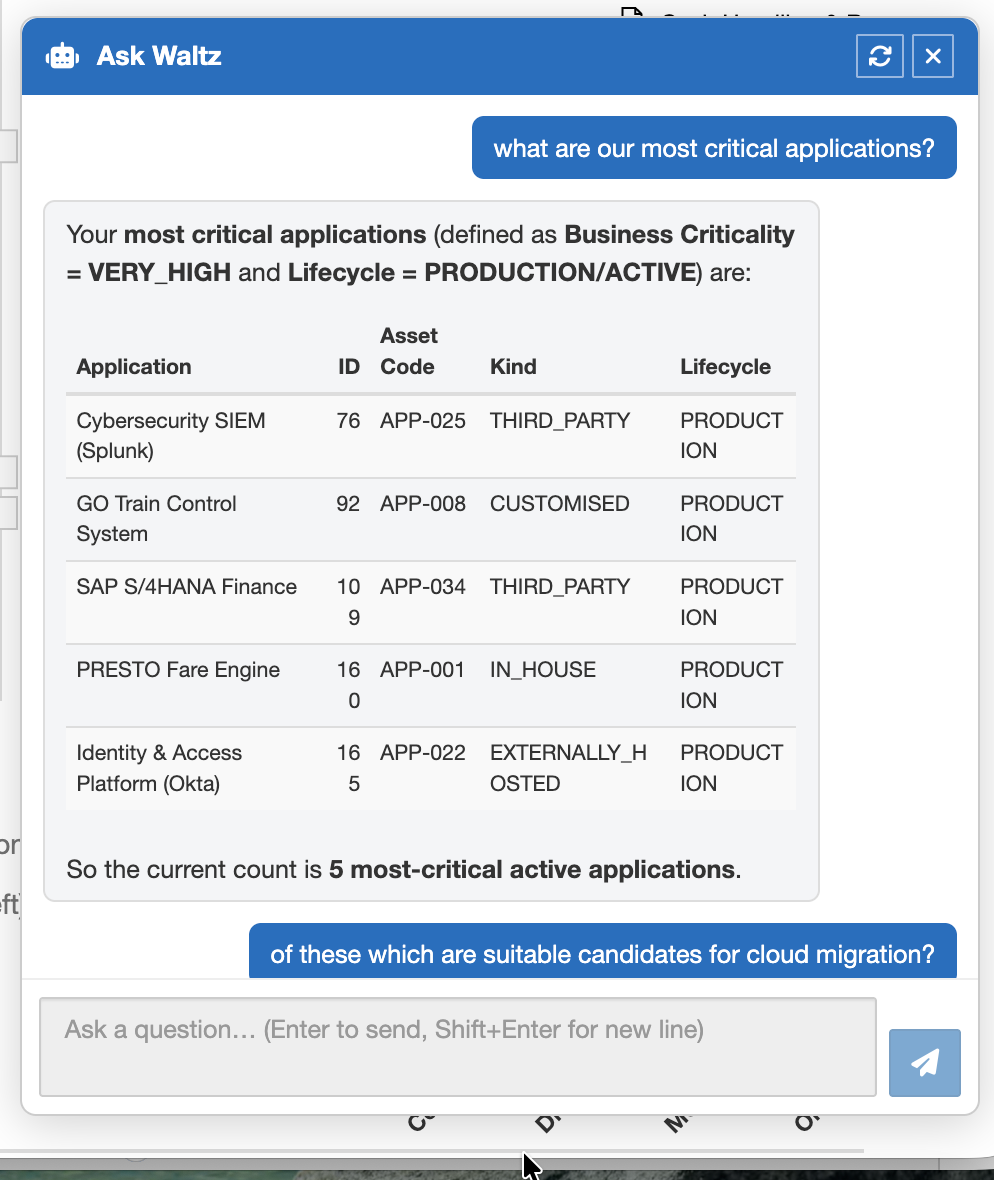
Once Waltz holds a rich, connected view of the estate; assessments, ownership, capabilities, data flows, dependencies, lifecycle states. The question of who can use that view becomes important. Architects and engineers can navigate it directly. Senior stakeholders typically cannot, and they are the people whose decisions the model exists to support.
An LLM with appropriate access becomes a useful interface to the model. Queries such as "show me applications rated Ready with conditions where the conditions involve regulatory approval and the business owner is in division X" today require either bespoke reporting or someone fluent in the data model. An LLM bridges that gap. The model becomes accessible to people who would otherwise need a translator, which is how it earns its place in governance forums and steering committees rather than just in architecture team meetings.
Some early POC screens below:
Drafting migration and assurance artefacts
Once an application is selected for a wave, there is substantial paperwork to produce: migration runbooks, change records, risk assessments, communication plans, post-migration assurance evidence. Much of this is templated and can be drafted from the structured data already in Waltz combined with the application's documentation, and possibly even represented in Waltz in the Notes feature.
This is where programme capacity is otherwise consumed. Engineers spend disproportionate time writing documents that mostly reformat information that already exists in structured form somewhere else. Automating the assembly of those documents + citations with the human signing off rather than authoring, frees capacity for the work that requires judgement.
The post-migration assurance angle is particularly relevant given the case study's emphasis on jurisdictional landing-zone compliance. Cross-referencing intended landing-zone decisions against actual deployment evidence, flagging discrepancies, and drafting assurance narratives is exactly the kind of structured-text task LLMs are well suited to, that said, these has all been done with task specific code that covers the automation problem well.
Where AI and ML tempt but disappoint
The temptations are equally important to name, because they are where AI investment most often goes wrong in this kind of programme.
Predicting readiness from infrastructure data alone
It is tempting to imagine training a model on "applications that migrated successfully" versus "applications that did not" and using it to score new candidates. This rarely works in practice. The dataset is small, the failure modes are heterogeneous, the ground truth is noisy, and "success" is hard to define consistently across applications and business contexts.
More fundamentally, the entire argument of the readiness model is that infrastructure data alone is insufficient. A predictive model trained on infrastructure features reproduces the failure mode the readiness model exists to fix. Better infrastructure-feature classifiers do not solve a problem that is fundamentally about business, regulatory, and dependency context.
Fully automated rating
An LLM can draft a rating. It cannot own one. Ratings carry governance weight, they justify investment decisions, regulatory positions, and sequencing choices. A rating with no accountable human behind it is a rating that does not survive its first challenge in a steering committee or audit.
This is not a courtesy point. It is a governance requirement. The readiness model is defensible because every rating has a human signature on it and a documented evidence trail. Removing the signature to claim full automation removes the property that makes the model useful in the first place.
"AI-driven migration sequencing"
Sequencing is constrained by dependencies, regulatory windows, business calendars, change freezes, contractual obligations, platform readiness, and team capacity. Most of these are hard constraints, not optimisation variables.
Constraint-based scheduling techniques genuinely help here and have for decades. Branding them as "AI-driven sequencing" adds nothing technical and tends to obscure what the constraints are. The risk is that opaque optimisation produces a plan nobody can defend when the first constraint shifts, which it will.
Treating LLM output as authoritative
LLMs hallucinate, particularly about specifics: version numbers, ownership, dates, regulatory clauses, contract terms. Anything an LLM produces about your estate must be treated as a draft to be verified against authoritative sources, not as fact.
The discipline that makes the readiness model defensible is the same discipline that protects against LLM error: written criteria, traceable evidence, human sign-off. Programmes that skip that discipline because the AI "sounded confident" end up with a portfolio of plausible sounding but unreliable ratings, which is a worse position than a smaller portfolio of carefully verified ones.
A sensible adoption sequence
The pattern that works in practice is to introduce AI capabilities in an order that builds trust before it builds dependence.
· Start with extraction. Use LLMs to draft application descriptions, ownership inferences, and dependency relationships from existing documentation. The output is reviewable, the cost of error is low, and the time savings are large.
· Move to assessment drafting. Once the team is comfortable with extraction quality, use LLMs to draft first-pass readiness assessments against the defined criteria. Keep the human-in-the-loop pattern explicit: every rating is reviewed and signed off.
· Add anomaly detection. Once a meaningful number of ratings exist, introduce ML-based consistency checks across the portfolio. This catches drift early and give the team confidence the model is being applied uniformly.
· Expose natural-language querying. Once the model is reliable, open it up to senior stakeholders through an LLM interface. This is where the investment in the underlying model pays off in governance value.
· Automate the artefact assembly. Last, automate the production of runbooks, change records, and assurance documents from the structured model. By this point the team has enough trust in the underlying data to delegate the assembly safely.
The order matters. Programmes that try to start at the end: automated artefact production from an LLM’s view of the estate, without the underlying model being trustworthy, produce confident-sounding outputs that will not survive scrutiny. Programmes that start at the beginning build the trust they need to use the more powerful capabilities later.
The architecture problem does not go away
The argument running through this whole series is that cloud migration is fundamentally an architecture visibility problem rather than an infrastructure problem. AI and ML do not change that. They change the cost of producing and maintaining the architecture view, which is significant; but the view itself, and the judgement applied to it, still has to exist.
Used well, AI makes a structured readiness model achievable in weeks rather than months, and maintainable as a living artefact rather than a frozen snapshot. Used badly, it produces a confident-sounding readiness rating with no defensible basis underneath it, which is exactly the failure mode the readiness model exists to prevent.
The right framing is not "what can AI do for cloud migration". It is "what does the migration programme need to do well, and where can AI accelerate that work without compromising the governance that makes it defensible". That framing puts the architecture model first and the AI tooling second.
HMx Labs helps organisations use Waltz to build evidence-based cloud migration programmes, and to integrate AI and ML capabilities where they accelerate that work without undermining its governance. Get in touch to discuss how this applies to your estate.



