Designing Safer Cloud Migration Waves with Waltz Dependency Mapping and AI Agents
Post 5 in a series on architecture-led cloud migration with Waltz. Earlier posts covered the case study, the argument for enterprise architecture before infrastructure, assessing cloud readiness across an application portfolio, and where AI and machine learning fit in Waltz-based migration planning. This post goes deeper into the dimension that most often determines whether a migration wave succeeds or unravels: dependencies. And how AI agents working over the Waltz model make a dependency-aware wave plan continuously defensible rather than a quarterly artefact.
Ask any experienced migration lead what derailed their last programme, and you will get the same answer in different words. It was rarely the application they were moving. It was something connected to it that nobody had fully mapped; a regulatory feed, a downstream consumer, a shared identity service, a batch scheduler, a firewall rule protecting an integration nobody had documented.
Hidden dependencies are where cloud migration plans go wrong, and they are precisely what a dependency-aware wave plan exists to manage.
Why wave plans built on preference fail
The default approach to wave planning combines three things: team preference, application priority, and technical readiness. All three are reasonable inputs. None of them, individually or together, is sufficient, because none reflects the structure of the estate.
An application can be a business-priority that is technically ready, and championed by an enthusiastic team, and still be a poor first-wave candidate. Why? because moving it creates operational risk to five other systems that are not ready, or because it consumes from a source whose migration is six months out. The opposite is also true: applications that look unattractive on every other dimension make ideal early movers if they happen to sit at the edge of the dependency graph, with nothing depending on them and nothing they depend on that is in scope.
A wave plan that ignores the dependency graph is, in effect, a plan built on the assumption that applications are independent. They almost never are.
What "dependency" actually means
The word covers a range of relationships with very different migration implications. A useful classification has three axes.
Direction. Upstream dependencies constrain when an application can move; downstream dependencies constrain how, because anything that breaks affects somebody else.
Type. Synchronous API calls behave differently from asynchronous messaging. Batch feeds behave differently from real-time integrations. Shared data stores behave differently from shared infrastructure. File transfers, shared identity, shared certificate authorities, shared scheduling, shared monitoring. Each has its own implications for whether and how the relationship can be temporarily bridged during migration.
Strength. A hard dependency means the consumer cannot function without the producer. A soft dependency degrades gracefully. Hard dependencies force tight sequencing or costly bridges; soft dependencies create manageable re-establishment windows. The distinction decides whether two applications must move together, whether one can move ahead of the other, and whether either can move at all without first remediating the relationship.
Modelling and feeding the graph
In Waltz, dependencies are modelled as relationships rather than notes. That distinction matters, because relationships can be queried, traversed, and reasoned about across thousands of applications; notes cannot.
A Waltz deployment built for migration planning captures logical flows (what data moves between which applications), physical flows (how each logical flow is realised: Kafka, SFTP, REST), interfaces with versioning and ownership, shared infrastructure dependencies modelled explicitly, and data classifications including residency and regulatory attributes.
The model is only as good as the evidence behind it, and no single source captures the full picture. CMDBs know what was registered; application teams know what they think they have; batch schedulers know what runs in what order; firewall rules know what was permitted to talk; static analysis knows what is configured; tracing knows what runs under load; network flow telemetry knows what moved across the wire.
In our deployments we wire several of these directly into Waltz, so the graph refreshes as evidence changes rather than as workshops are scheduled. The architecture team becomes the curator of the model, not its author, which is the only sustainable posture for a graph that will need to support wave planning for several years.
The interesting work is the reconciliation. A connection in network flow data with no documented integration is a question. A documented integration never seen in traffic is a different question. A scheduler job nobody recognises is a third. These discrepancies are exactly where hidden dependencies live, and they are the first thing the AI agents we deploy against Waltz are designed to surface.
From graph to wave: three sequencing decisions
Once the graph is in place, wave planning becomes a small number of repeated decisions. The standard heuristics still apply, non-production before production, small early waves, business calendar awareness, simpler workloads first whilst the hyperscaler playbooks cover the operational mechanics in detail. What dependency-aware planning adds is the structural constraint underneath: the order of moves is determined by the shape of the graph, and any heuristic that contradicts it pays for the contradiction at execution time.
Independent movers.
Applications whose neighbourhood in the graph is stable across the proposed migration window: no hard upstream dependencies mid-migration, no downstream consumers affected beyond what their owners have agreed. They build programme confidence, exercise the landing zones, and validate the operational model. They populate the early waves.
Move-together groups.
Tightly coupled systems that share state through a database, exchange synchronous traffic at low latency, or participate in the same transaction boundary. A trading-system order manager and its risk engine. A reconciliation engine and its position store. These move together or they create avoidable risk. The graph's job is to make these groups visible during planning, before they assert themselves as emergency coordination problems.
Move-after constraints.
Applications that can move independently but only after a specific upstream is in place. A reporting platform after its data sources have settled. A downstream consumer after its strategic upstream is generally available in cloud. The cost of ignoring move-after constraints is a fragile cross-environment connection that usually works, until it does not, at which point the incident is somebody's.
A worked example
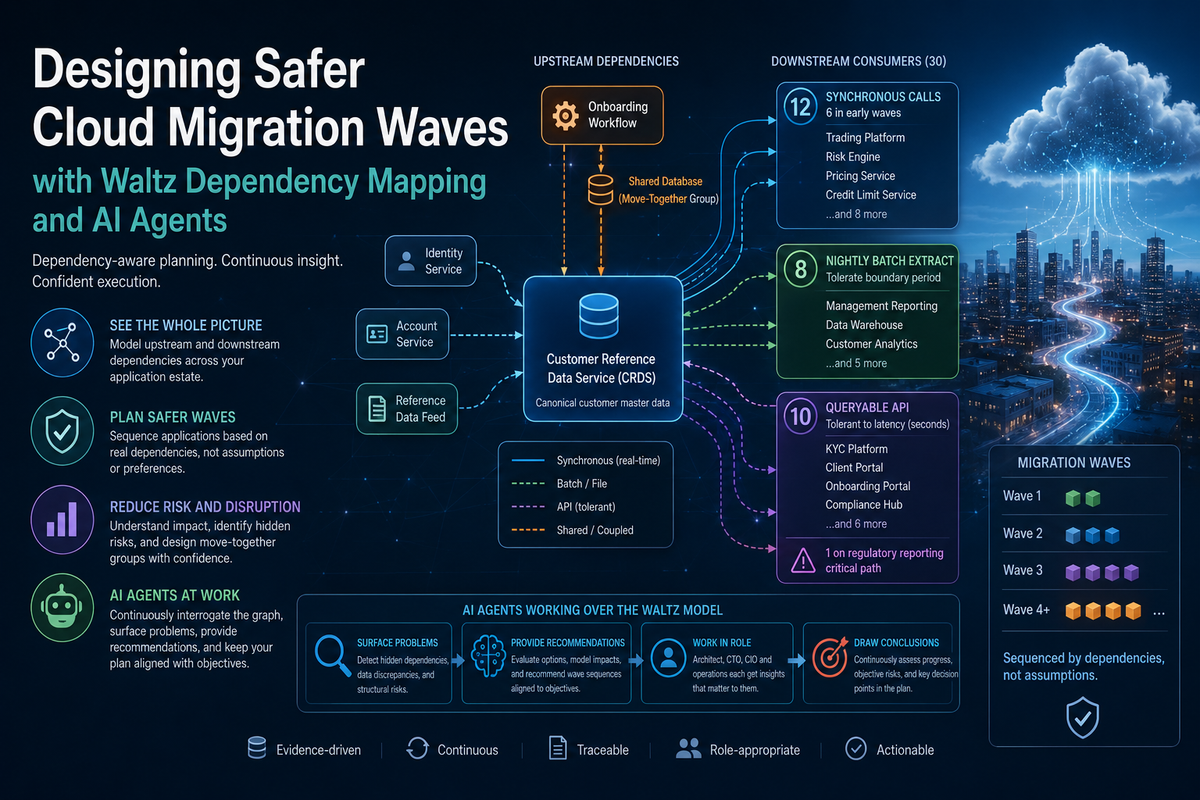
Consider a Customer Reference Data Service (CRDS) sitting at the centre of a financial services estate. CRDS holds canonical customer master data, consumed by thirty downstream applications across trading, risk, reporting, KYC, and onboarding.
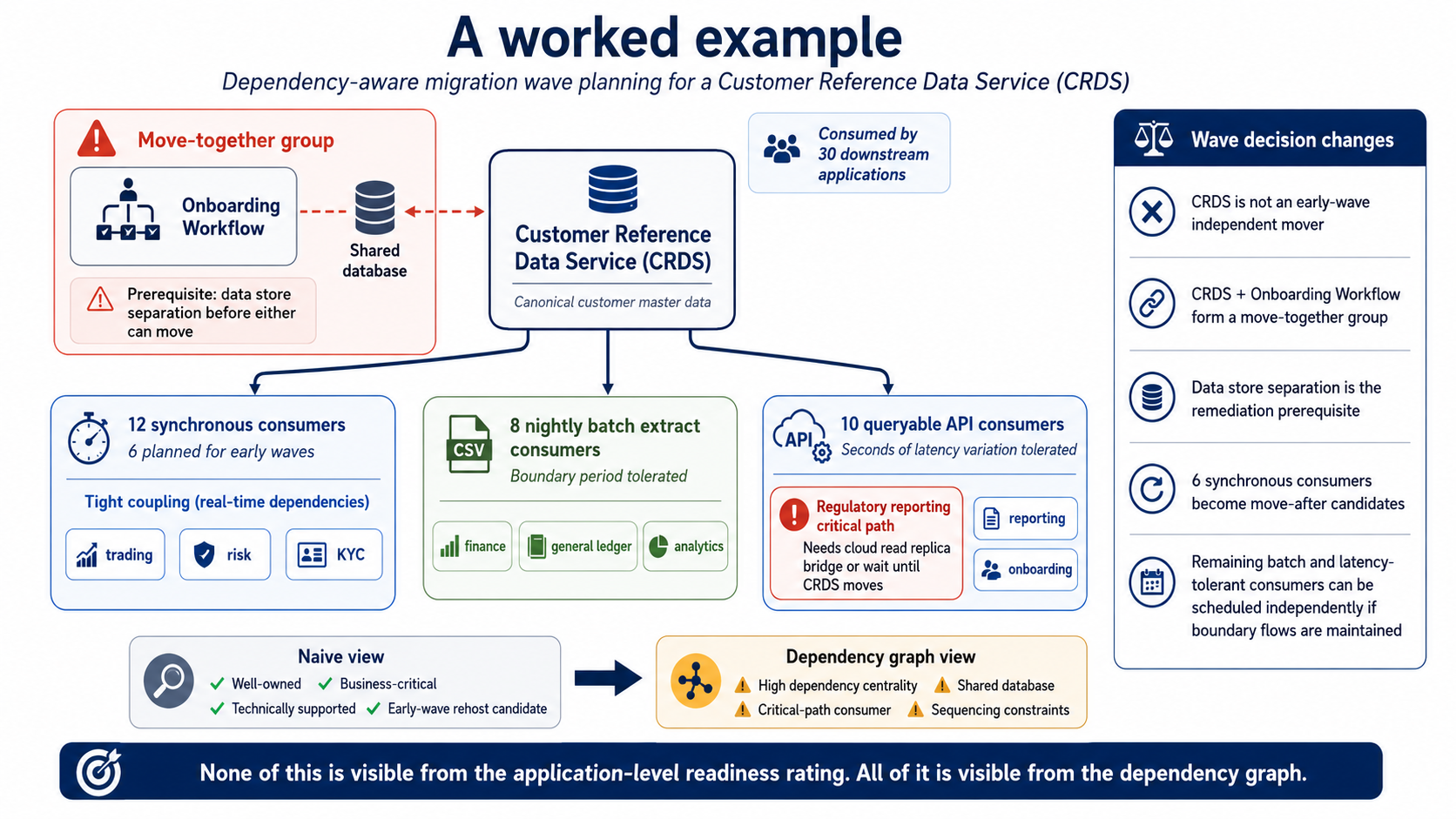
A naive wave plan would assess CRDS on its own merits: well-owned, business-critical, technically supported, an early-wave rehost candidate.
The graph tells a different story. Of the thirty consumers:
· Twelve use synchronous calls and six of those are themselves planned for early waves.
· Eight read CRDS via a nightly batch extract; these tolerate a boundary period.
· The remaining ten use a queryable API with tolerance for seconds of latency variation
o except one that sits on a regulatory reporting critical path.
· The most important point of all: CRDS shares a database with the upstream onboarding workflow, which is itself a migration candidate.
That is not a dependency; it is a move-together group with a remediation prerequisite (data store separation) before either can move.
The wave decision changes accordingly. CRDS is not an early-wave independent mover. It is the heart of a move-together group whose data store must be untangled first. Six synchronous consumers become move-after candidates. The critical-path regulatory consumer needs a specific bridge, a read replica in the cloud landing zone — or cannot be scheduled until CRDS has moved. The remaining consumers can be scheduled independently provided the batch and tolerant flows are maintained across the boundary.
None of this is visible from the application-level readiness rating. All of it is visible from the dependency graph.
How AI agents work the graph
The previous post in this series covered where AI and machine learning fit in Waltz-based migration planning at a high level. Dependency-aware wave planning is where that capability becomes most concrete, because the graph is a rich, structured artefact that benefits substantially from agentic reasoning. We deploy AI agents that interrogate the Waltz model through precise entity queries, analytical pattern-finding across the portfolio, and semantic similarity for concepts the structured model does not express and through personas do four kinds of work that human teams find expensive at portfolio scale.
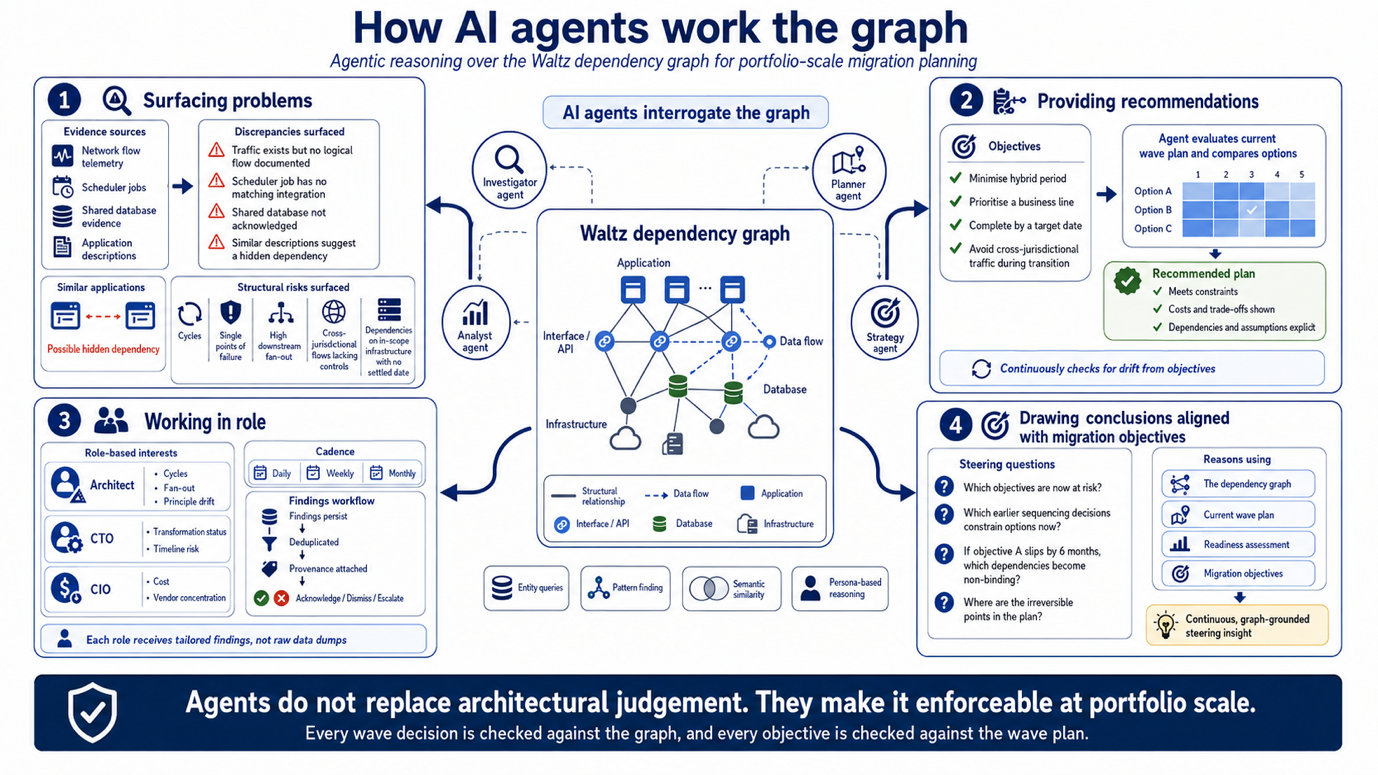
Surfacing problems.
Agents continuously compare the graph against the evidence sources feeding it. Where network flow telemetry shows traffic the logical flow model does not, where a scheduler job has no corresponding integration, where two systems share a database that neither application owner has acknowledged, the agent raises it as a question with the supporting evidence attached.
The volume of such discrepancies in a large estate is what makes manual reconciliation prohibitive; agents make it tractable. They also surface structural risks the graph reveals but humans rarely think to look for: cycles, single points of failure with high downstream fan-out, cross-jurisdictional flows lacking documented controls, dependencies on infrastructure that is itself in scope for migration with no settled date.
Some of the most useful problem-finding uses semantic similarity rather than structural traversal. Two applications whose metadata suggest they handle the same data, with no documented flow between them, are a hidden dependency the structured graph cannot surface but a semantic query can, these are precisely the cases that turn into late-stage migration surprises.
Providing recommendations.
Agents do not only respond to questions. Given the graph and a set of stated migration objectives such as:
1. Minimise hybrid period
2. Prioritise a particular business line
3. Complete by a specific date
4. Avoid cross-jurisdictional traffic during transition
They continuously evaluate the current wave plan against those objectives and raise findings when it drifts. Where they are asked for a new plan rather than a check on an existing one, the output is not "here is the answer". It is "here is a plan that satisfies these constraints, here is what it costs, and here is what it depends on", with the working shown. The agent's value is that it explores the option space at a scale and consistency human planners cannot, presents its choices in a form that can be challenged, and does so continuously rather than only when somebody remembers to ask.
Working in role.
The same graph looks different to different stakeholders.
· An architect cares about structural risks like cycles, fan-out, principle drift.
· A CTO cares about transformation status and timeline risk.
· A CIO cares about cost and vendor concentration in upcoming waves.
Agents tuned to a specific role's concerns produce findings shaped for that audience, on a cadence appropriate to it. For example, daily for operational hygiene, weekly for portfolio-level concentration, monthly for architectural principle drift rather than dumping the same raw analysis on everyone. Findings persist across runs, are deduplicated so the same concern is not raised three times, carry the provenance of every query and entity that produced them, and can be acknowledged, dismissed, or escalated. The result is that the wave plan is under continuous, role-appropriate scrutiny rather than waiting for the next steering group to surface its problems.
Drawing conclusions aligned with migration objectives.
The harder and more interesting work is reasoning at the level of programme objectives rather than individual moves. An agent with access to the graph, the wave plan, the readiness assessment, and the stated objectives can answer questions that are otherwise hard to evaluate. For example:
· Given current progress, which objectives are now at risk?
· Which sequencing decisions taken in earlier waves are constraining options now?
· If we accept a six-month delay on objective A, which dependencies become non-binding?
· Where in the plan is the irreversibility, the points beyond which retreat is expensive?
These are the questions migration steering groups try to answer in quarterly reviews. Agents working over the Waltz model make them continuously available, grounded in the architecture rather than in opinion.
The agents do not replace architectural judgement. They make architectural judgement enforceable at portfolio scale, by ensuring every wave decision is checked against the graph and every objective is checked against the wave plan. The architect's role is what it should be: directing reasoning, not performing reconciliation.
Hidden dependencies and foundational services
Even with disciplined modelling, some dependencies are reliably missed. They can hide:
· in connection strings and configuration files (often the most authoritative source of integration information, and also often the least documented)
· in firewall rules that have been in place for years and that nobody can remember why
· in batch schedulers that encode the ordering operations actually relies on, in shared infrastructure too universal to feature in application diagrams
· in implicit assumptions about latency, location, and time that behave like dependencies when they break,
· in operational dependencies: shared on-call teams, shared deployment pipelines, shared change windows
None of the above are in any application model at all. When they fail, they fail in predictable ways: hidden upstream services left behind, identity or certificate mismatches, DNS changes applied out of order, third-party allowlists blocking changed source IPs, data synchronisation delays, broken timing assumptions. None of this is exotic. All of it is preventable, if the graph has been built well enough to see it coming.
Some applications themselves are foundational i.e. a reference data service consumed by half the estate, an enterprise scheduler, a strategic API gateway. The graph reveals them by their downstream fan-out. They sit in wave zero or a dedicated early wave; they are not interchangeable with the rest of the portfolio.
Bridges and the limits of sequencing
Not every dependency can be resolved by sequencing. Some applications have to move ahead of their dependencies for example, a data centre exit deadline, a strategic platform decision, a regulatory window. The dependency model does not block the move; it prices it.
The pricing is the cost of the bridge. Hybrid connectivity, read replicas, dual-write patterns, event mirroring, identity federation, temporary network extensions. All are valid migration techniques, and all are operational debt for as long as they are in place. The wave plan should be explicit about which bridges are being built, what they cost to run, and when they will be retired. A bridge for six weeks during a planned wave is a reasonable migration cost. A bridge that becomes permanent because the downstream never moved is an architectural problem the migration created. The graph is what lets you tell the difference at planning time, when you can still do something about it.
What this changes
The argument running through this series is that cloud migration is fundamentally an architecture visibility problem. Dependency-aware wave planning is where that argument becomes most concrete, because the dependency graph is the single piece of architecture that most directly determines whether a wave succeeds or fails.
The change a dependency-aware approach enables is not a different list of applications or a different total migration timeline. It is a different basis for sequencing. Applications are scheduled because of where they sit in the graph, not because of who shouted loudest at the planning workshop. Move-together groups are recognised as units. Move-after constraints are respected. Bridges are designed deliberately rather than improvised under pressure. AI agents catch the discrepancies, propose the trade-offs, and check the plan against the objectives continuously, rather than letting all of this accumulate to a quarterly review.
In the case study estate this series builds on, the documented outcomes included faster prioritisation across a large and diverse portfolio, better sequencing of migration waves based on real dependencies, and reduced risk of disruption caused by hidden interconnections. None of those were achieved by adding effort to the programme. They were achieved by directing the same effort against a better-shaped problem.
The migration plan stops being a list of applications and becomes a sequenced traversal of an architecture model, supported by agents that keep the model honest and the plan defensible.
That is the difference between a wave plan that looks reasonable in PowerPoint and a wave plan that survives contact with execution.
HMx Labs helps organisations use Waltz, augmented with AI agents, to map dependencies, design dependency-aware migration waves, and build evidence-based migration programmes that survive scrutiny from architecture, delivery, and governance teams alike. If you are planning a large-scale migration and want to move beyond preference-led wave design, get in touch.



